Earlier this year we published a post titled Implementing A Debugger: The Fundamentals. This post gave an overview of debuggers, what they do, and how they work. In today’s post, we build upon this knowledge and talk about our journey of extending Backtrace’s debugger to support Go.
Intro
If you have the time and haven’t read Implement A Debugger: The Fundemantals, we highly recommend you do so. This post builds upon terms and knowledge discussed there. For the sake of those who don’t have the time, here are some of the high-level points:
- Debuggers leverage debug information and a process’s state in memory to translate raw state into a form more easily understood by users, aka symbols. Think threads, callstack, variables, etc.
- Stack winding gives us the callstack, which tells users the location in code the process is currently executing and the function calls that led up to it.
- In order to synthesize variables, the debugger must evaluate debug information to understand characteristics of the variable (type, width, etc) and learn where variables are stored. This debug information is generated at compile time and is typically in a format called DWARF for Linux-based applications.
Finally, before we jump head first, a big thanks to everyone that helped complete this work and write this article.
Background
Backtrace’s journey in building a Go debugger didn’t start from square 0. We already had a full-fledged debugger built to take snapshots of C/C++ applications at the time of error. But as any gopher out there knows, existing C/C++ tools like GDB don’t work with Go out of the box. There were existing debuggers like Delve but these weren’t well suited for our use case, which was to quickly capture the state of the application at a point in time and send it into our turn-key debugging platform.
Go’s DWARF
Let’s start off by exploring some of the debug information (aka DWARF)
generated by the Go compiler, gc, that caused our debugger to fail. Please
note, this post focuses on gc and not gccgo (an interesting follow-up post.)
For brevity, we’ll be referring to Backtrace’s debugger as BT for the rest of
this article.
Offset encoding
From the start, BT had problems parsing the debug information
generated by the Go compiler. While parsing individual DIEs,
BT would throw the error: Invalid abbreviation code. Closer inspection of the
abbreviation code table (readelf --debug-dump=abbrev) and debug info (readelf --debug-dump=info) didn’t show the abbreviation code in question.
This led us to the conclusion that we were traversing the DWARF information
incorrectly, which is likely due to reading invalid offsets. Through a variety
of methods to pinpoint where parsing went awry, we landed on DW_FORM_ref_addr,
specifically our handling of it, as the culprit.
DW_FORM_ref_addr links to other locations in the .debug_info section (this
is where DWARF is stored.) The data associated with this attribute stores the
byte offset relative to the start of the .debug_info section. Debug
information may use this attribute to link to type debug information common to
many different variables (i.e., many variables will have a type field with a
DW_FORM_ref_addr attribute, the values of which resolve to the same offset).
The interpretation of this attribute changed between DWARF2 and DWARF3:
References that use the attribute form DW_FORM_ref_addr are specified to be four bytes in the DWARF 32-bit format and eight bytes in the DWARF 64-bit format, while DWARF Version 2 specifies that such references have the same size as an address on the target system (see Sections 7.4 and 7.5.4). Source: DWARF3 Standard, Page 4
Previously, we were relying purely on the detected DWARF file format to determine offset sizes. For DWARF3, the 32-bit format has offsets that are 4 bytes in size; in the 64-bit format, offsets are 8 bytes. For DWARF2, these offsets were the same size as a pointer on the target system. Go emits DWARF2 in the 32-bit format.
Thus, our first fix was to read pointer-size bytes for DW_FORM_ref_addr if
DWARF2 is detected.
$ readelf --debug-dump=info consul | head -n 7
Contents of the .debug_info section:
Compilation Unit @ offset 0x0:
Length: 0x34ac98 (32-bit)
Version: 2
Abbrev Offset: 0x0
Pointer Size: 8
Thread detection
On Linux, Go doesn’t use the standard NPTL
to create threads and instead directly uses the clone system call. This broke
BT, which previously relied on libthread_db to find and iterate over the
threads of a process. Luckily, Linux provides an alternate way to accomplish
this via the /proc filesystem. By scanning /proc/<pid>/task, BT is able to
discover the set of threads in a Go process and continue in the process of
unwinding. This work also gave us an alternate thread listing in cases where
libthread_db’s internal structures were corrupt.
Type dereferencing
Dereferencing usually involves a pointer/reference. In this case the type of said pointer/reference indicates the type of the variable being pointed to. Dereferencing isn’t as simple with Go, where some complex types contain dynamic arrays which may have debug information with multiple, indirect qualifiers (e.g. typedefs.) In this situation, the type of the element for these arrays is stored as an attribute in the DIE belonging to the complex type. Below is an example of such attributes for a slice type:
<1><4223d>: Abbrev Number: 19 (DW_TAG_structure_type)
<4223e> DW_AT_name : []int
<42244> DW_AT_byte_size : 24
<42245> Unknown AT value: 2900: 23
<42246> Unknown AT value: 2902: <0x40586>
The unknown attributes are Go-specific attributes not included in the DWARF
specifications; here, 0x2900 contains the Go type (ignoring its tag – i.e. a channel, a slice, etc.),
and 0x2902 points to the element type of the underlying array.
This required us to add support for dereferencing arbitrary addresses using declared types rather than the type associated with a pointer variable.
Typename cache
We could stop there if we always had the type attribute available when dereferencing, but this isn’t always the case as is seen when dealing with Go interfaces.
A little background: In Go, variables can have an interface as its type. Such
variables are called interface values. Interface values can be thought of as a
pair: (interface type, concrete type). In gc, interface values are
represented as:
- A pointer to an entry in the interface table (itable), which contains the associated concrete type and a list of function pointers associated with the concrete type that satisfy the interface type.
- Interface’s data (aka the concrete type).
Go also allows programmers to dynamically change/convert the interface associated with an interface value. This forces Go to generate the itable at runtime as it isn’t always tenable to precompute the set of (interface type, concrete type) pairs. If you are interested in learning more about the magic behind Go interfaces, we recommend reading Russ Cox’s article on them.
We’re sure this presented a particularly interesting challenge to the Go team when
considering what debug information to generate for interface values. For gc,
the debug type information for the associated interface value is represented by a plain
string (not a DWARF type attribute). Note, aspects of this changed in 1.7
which is discussed in the Go 1.7 section further in this post.
We needed to combine our ability to deference data via type, described in the section above, and new functionality to map from the string representing the type to the DWARF type, if available, to be able to understand interfaces in BT. We called this map the typename cache and built it to leverage the way we parse DWARF data to avoid any additional passes on the debug information. We simply cache type DIEs as they are seen, and look them up whenever we encounter type strings.
Multidimensional arrays
For some Go types, Go emits the DWARF to describe a multidimensional array but
does not follow the DWARF specification on multidimensional arrays. As specified
by DWARF, a multidimensional array will be represented by an array type DIE with
multiple child DW_TAG_subrange_type or DW_TAG_enumeration_type DIEs, each
one representing a dimension of the array:
Each array dimension is described by a debugging information entry with either
the tag DW_TAG_subrange_type or the tag DW_TAG_enumeration_type. These entries
are children of the array type entry and are ordered to reflect the appearance
of the dimensions in the source program (i.e. leftmost dimension first, next
to leftmost second, and so on).
Source: DWARF2 Standard, Page 39
Instead of the array type DIE having a child DIE for each dimension,
it has one subrange_type DIE for its leftmost dimension and links to
an array type DIE of the subsequent dimension through its DW_AT_type
attribute. This repeats until the base type of the array is reached. You can
conceptualize this as representing a multidimensional array as a linked list of
types instead of a type tree.
Thus, we had to add a special case to support this form of multidimensional array representation in BT. Below are some examples of multidimensional arrays in Go and C.
Example Go output
Multidimensional array variable declaration:
func main() {
multi_d3_v := [3][2][2]int{
{ {3, 4}, {1, 2} },
{ {3, 4}, {3, 4} },
{ {3, 4}, {5, 6} },
}
}
Variable information:
<2><7ff>: Abbrev Number: 4 (DW_TAG_variable)
<800> DW_AT_name : multi_d3_v
<80b> DW_AT_location : ...
<811> DW_AT_type : <0x4808d>
Type information:
<1><48070>: Abbrev Number: 12 (DW_TAG_array_type)
<48071> DW_AT_name : [2]int
<48078> DW_AT_type : <0x40586>
<48080> DW_AT_byte_size : 16
<48081> Unknown AT value: 2900: 17
<2><48082>: Abbrev Number: 9 (DW_TAG_subrange_type)
<48083> DW_AT_type : <0x3ef88>
<4808b> DW_AT_count : 2
<2><4808c>: Abbrev Number: 0
<1><4808d>: Abbrev Number: 12 (DW_TAG_array_type)
<4808e> DW_AT_name : [3][2][2]int
<4809b> DW_AT_type : <0x480b0>
<480a3> DW_AT_byte_size : 96
<480a4> Unknown AT value: 2900: 17
<2><480a5>: Abbrev Number: 9 (DW_TAG_subrange_type)
<480a6> DW_AT_type : <0x3ef88>
<480ae> DW_AT_count : 3
<2><480af>: Abbrev Number: 0
<1><480b0>: Abbrev Number: 12 (DW_TAG_array_type)
<480b1> DW_AT_name : [2][2]int
<480bb> DW_AT_type : <0x48070>
<480c3> DW_AT_byte_size : 32
<480c4> Unknown AT value: 2900: 17
<2><480c5>: Abbrev Number: 9 (DW_TAG_subrange_type)
<480c6> DW_AT_type : <0x3ef88>
<480ce> DW_AT_count : 2
<2><480cf>: Abbrev Number: 0
Example C output
Multidimensional array variable declaration:
int
main()
{
int a[3][2] = {
[0] = {0, 1},
[1] = {1, 2},
[2] = {2, 3}
};
Variable information:
<2><b1>: Abbrev Number: 6 (DW_TAG_variable)
<b2> DW_AT_name : a
<b6> DW_AT_type : <0xbe>
<ba> DW_AT_location : ...
Type information:
<1><be>: Abbrev Number: 7 (DW_TAG_array_type)
<bf> DW_AT_type : <0x57>
<2><c3>: Abbrev Number: 8 (DW_TAG_subrange_type)
<c4> DW_AT_type : <0x65>
<c8> DW_AT_upper_bound : 2
<2><c9>: Abbrev Number: 8 (DW_TAG_subrange_type)
<ca> DW_AT_type : <0x65>
<ce> DW_AT_upper_bound : 1
Goroutines
Goroutines are not typical threads. They aren’t listed in the /proc file
system. They don’t follow the common structure associated with pthreads. We
could go on, but you get the point. Regardless of this difference, it was
important for BT to identify all goroutines (including callstacks, variables)
associated with a Go process; otherwise BT snapshots would be incomplete.
Step 1 in this process was to gather the complete list of goroutines stored in
the global slice allgs. This slice stores all goroutines including
goroutines created by the Go runtime (garbage collection, signal handling) and
ones marked “dead.” Other sources, such as the global or per-processor run queues,
only provide runnable and ready goroutines.
Once this is done, BT filters out “dead” goroutines and system goroutines (if configured to do so). For each of the remaining goroutines, BT:
- unwinds the callstack
- extracts the address range and size of the goroutine’s stack
- extracts the Go statement that created the goroutine
- collects the wait reason and wait duration for any goroutine in the “waiting” state.
This is not an exhaustive list, but covers some of the more important per-goroutine processing BT does.
Special-case unwinding
The first item when processing a go routine is to unwind the callstack. Unfortunately, even unwinding wasn’t straight forward. Some goroutines require special unwinding logic under certain conditions; one such condition is related to the garbage collector.
By default, Go’s garbage collector inserts a return PC (referred to as stack barriers) at expotentially-spaced frames. This stack barrier acts as a marker to the GC during stack scanning/mark-termination phase – only the portion of the stack further down from the latest valid stack barrier must be scanned.
Any unwinding must resolve these stack barriers to accurately parse deep stacks.
If you happen run into the need to do this yourself, Go’s runtime.Callers(),
which internally calls runtime.gentraceback (and is what you’d see by default
when there’s an unhandled panic), handles this situation.
The solution here is straightforward. Stack barriers are stored at the base
(uppermost region) of a goroutine’s stack, as can be seen in the following
excerpt from runtime.stackalloc():
v := sysAlloc(round(uintptr(n), _PageSize), &memstats.stacks_sys)
if v == nil {
throw("out of memory (stackalloc)")
}
top := uintptr(n) - nstkbar
stkbarSlice := slice{add(v, top), 0, maxstkbar}
return stack{uintptr(v), uintptr(v) + top}, *(*[]stkbar)(unsafe.Pointer(&stkbarSlice))
If the stackBarrierPC is encountered while unwinding, we access the
appropriate stack barrier stored at the base of the goroutine stack and
restore the original PC. We continue unwinding using the original PC.
There are other situations that require special unwinding, most of which are
handled in runtime.gentraceback(). This is also a good time to shout out to
the work
being done by Austin Clements to remove these stack barriers after mark termination. Austin also has a
new proposal to remove stack re-scanning
which may remove stack barriers altogether.
Bonus: Pretty printing
At this point, we were able to interpret a Go program from BT but we knew we weren’t done. To truly inspect raw program state in a form that more closely resembled the source code written, we added pretty printers for complex Go types like channels, maps, and slices. These pretty printers took the data associated with these complex types and generated alternate forms that could be easily displayed by our web and terminal UIs. Data structures that allow hetergeneous types in certain members, like keys of a Go map, meant that the pretty printers needed to be composable and context-aware.
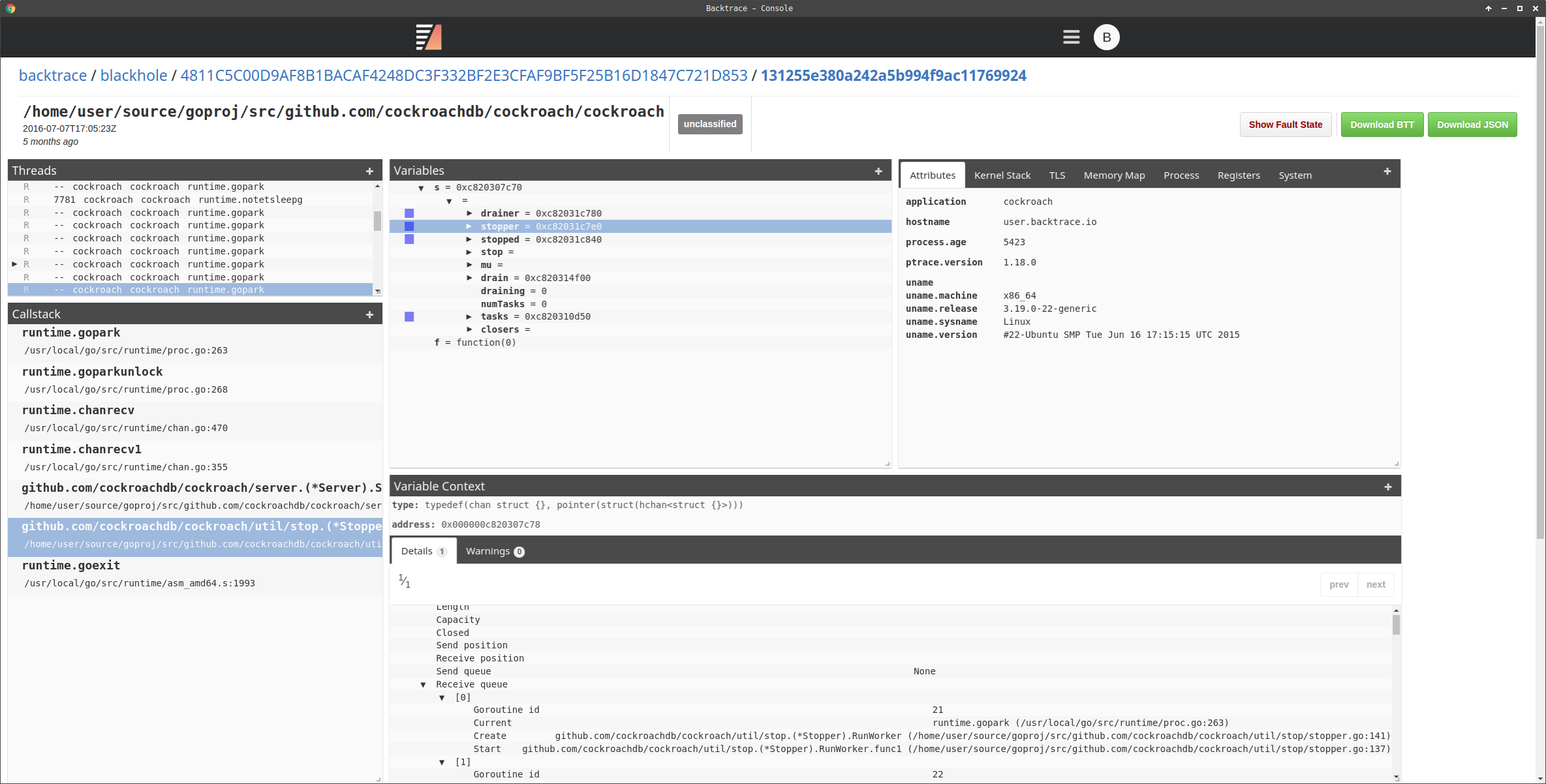
Go Channel Pretty Printing
Go’s scheduler has the task of scheduling goroutines across a set of go runtime threads. Internally, it has a number of interesting data points that could prove incredibly valuable when investigating the state of a Go process, like the number of idle threads, whether the garbage collector is waiting, and global and per-processor run queues. BT also captures processor-specific information: the number of scheduler and syscall ticks, the state of the processor, etc. This information provides hints to things like imbalanced workloads, unusual number of syscalls, and unexpected goroutine spawning.
Go 1.7
The release of Go 1.7 changed a couple of things that BT relied on. First, the
implementation of interfaces changed, with some fields changing in meaning and
name. A more in-depth analysis will have to wait until a follow-up blog post. At
a high-level, interfaces with types known at compile time have their type names
stored in the global read-only moduledata. Types created at runtime are now
stored on the heap and built on demand.
Second, in some cases, the kernel thread ID is not being recorded to the
runtime.goroutine structure. BT depended on this ID to associate goroutines
with kernel threads. This association was used to mark goroutines as relevant to
root-cause investigation if a fault occured. We worked around this by inspecting
a goroutine’s signal and capturing the goroutine that invoked our debugger (when
using our library).
Outstanding issues
Variable location lists: Go’s currently emitted DWARF information does not properly indicate the scope of a variable. If a function has multiple variables of the same name with different scopes, any Go debugger will have multiple values for the same variable (unless it arbitrarily picks one). Variables not currently in scope according to the PC may have garbage values.
For Go1.7,
gcsometimes generates dwarf entries for local variables that are not declared by the original source program. We do not have a good way to differentiate them from actual local variables in the original source. This issue is still being investigated
Conclusion
Several paragraphs later, Backtrace has a fully functioning debugger for Go. There are still improvements to be made, like capturing internal information from Go’s garbage collector but what we have today gives users the ability to gain deep introspection into their Go applications at the time of error, across their environments.
Our Go debugger is bundled with the enterprise version of Backtrace. If you’re interested in trying it out, sign up for a free trial.