To make a long story short, it’s almost easy, now that tracing is available on commodity hardware, especially with a small library to handle platform-specific setup.
Here’s a graph of the empirical distribution functions for the number of calls into OpenSSL 1.0.1f it takes for Hypothesis to find Heartbleed, given a description of the format for Heartbeat requests (“grammar”), and the same with additional branch coverage feedback (“bts”, for Intel Branch Trace Store).
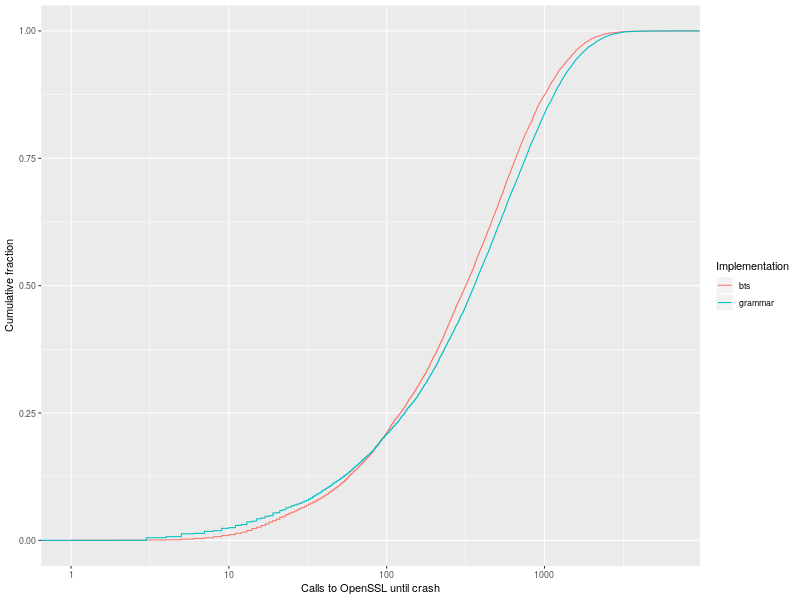
On average, knowing the grammar for Heartbeat requests lets Hypothesis find the vulnerability after 535 calls to OpenSSL; when we add branch coverage feedback, the average goes down to 4731 calls, 11.5% faster. The plot shows that, as long as we have time for more than 100 calls to OpenSSL, branch coverage information makes it more likely that Hypothesis will find Heartbleed for any attempt budget. I’ll describe this experiment in more details later in the post; first, why did I ask that question?
Enumerating test cases by hand is a waste of people’s time
I care about efficiently generating test cases because I believe that most of the time people spend writing, reviewing, and maintaining classic small or medium tests is misallocated. There’s a place for them, same as there is for manual QA testing… but their returns curve is strongly concave.
Here are the sort of things I want to know when I look at typical unit test code:
- Why do we make this exact assertion; what makes a result acceptable?2
- Why do we feed this or that input; what makes input data useful or interesting?
- What is expected to change when I tweak the external behaviour of the system under test;3 how are answers to the previous two questions encoded?
As programmers, I think it’s natural to say that, if we need to formalize how we come up with assertions, or how we decide what inputs to use during testing, we should express that in code. But once we have that code, why would we enumerate test cases manually? That’s a job for a computer!
Property-based testing at Backtrace
I have such conviction in this thesis that, as soon as I took over the query processing component (a library written in C with a dash of intrinsics and inline assembly) at Backtrace, I introduced a new testing approach based on Hypothesis. The query engine was always designed and built as a discrete library, so it didn’t take too much work to disentangle it from other pieces of business logic. That let us quickly add coverage for the external interface (partial coverage, this is still work in progress), as well as for key internal components that we chose to expose for testing.
Along the way, I had to answer a few reasonable questions:
- What is Hypothesis?
- Why Hypothesis?
- Wait, there are multiple language backends for Hypothesis, but none for C or C++; how does that work?
What is Hypothesis?
Hypothesis is a Python library that helps programmers generate test cases programmatically, and handles a lot of the annoying work involved in making such generators practical to use. Here’s an excerpt from real test code for our vectorised operations on arrays of 64-bit integers.
# test_u64_block.py
from hypothesis import given
import hypothesis.strategies as st
def check_u64_bitmask(booleans):
"""Given a list of 8 booleans, generates the corresponding array of
u64 masks, and checks that they are correctly compressed to a u8
bitmask.
"""
expected = 0
for i, value in enumerate(booleans):
if value:
expected |= 1 << i
masks = struct.pack("8Q", *[2 ** 64 - 1 if boolean else 0 for boolean in booleans])
assert expected == C.u64_block_bitmask(FFI.from_buffer("uint64_t[]", masks))
class TestU64BlockOp(TestCase):
@given(bits=st.lists(st.booleans(), min_size=8, max_size=8))
def test_u64_block_bitmask(self, bits):
check_u64_bitmask(bits)
A key component of these operations is a C (SSE intrinsics, really) function that accepts eight 64-bit masks as four 128-bit SSE registers (one pair of masks per register),
and returns a byte, with one bit per mask.
In order to test that logic, we expose u64_block_bitmask, a wrapper that accepts an array of eight masks
and forwards its contents to the mask-to-bit function.
check_u64_bitmask calls that wrapper function from Python, and asserts that its return value is as expected: 1 for each mask that’s all 1s, and 0 for each mask that’s all 0s.
We turn check_u64_bitmask into a test cases generator
by annotating the test method test_u64_block_bitmask with a @given decorator
that asks Hypothesis to generate arbitrary lists of eight booleans.
Of course, there are only 256 lists of eight booleans; we should test that exhaustively.
Hypothesis has the @example decorator,
so it’s really easy to implement our own Python decorator to apply
hypothesis.example once for each element in an iterable.
# test_u64_block.py
def all_examples(examples):
"""Applies a list of hypothesis.examples."""
def apply_examples(fn):
for ex in reversed(list(examples)):
fn = example(ex)(fn)
return apply_examples
def extract_bits(number, num_bits):
"""Converts the num_bits bit number to a list of booleans."""
return [(number & (1 << shift)) != 0 for shift in range(num_bits)]
class TestU64BlockOp(TestCase):
@all_examples(extract_bits(i, 8) for i in range(256))
@given(bits=st.lists(st.booleans(), min_size=8, max_size=8))
def test_u64_block_bitmask(self, bits):
check_u64_bitmask(bits)
That’s pretty cool, but we could enumerate that more efficiently in C. Where Hypothesis shines is in reporting easily actionable failures. We’re wasting computer time in order to save developer time, and that’s usually a reasonable trade-off. For example, here’s what Hypothesis spits back via pytest when I introduce a bug to ignore the last pair of masks, masks 6 and 7, and instead reuse the register that holds masks 4 and 5 (a mistake that’s surprisingly easy to make when writing intrinsics by hand).
booleans = [False, False, False, False, False, False, ...]
def check_u64_bitmask(booleans):
"""Given a list of 8 booleans, generates the corresponding array of
u64 masks, and checks that they are correctly compressed to a u8
bitmask.
"""
expected = 0
for i, value in enumerate(booleans):
if value:
expected |= 1 << i
masks = struct.pack("8Q", *[2 ** 64 - 1 if boolean else 0 for boolean in booleans])
> assert expected == C.u64_block_bitmask(FFI.from_buffer("uint64_t[]", masks))
E AssertionError: assert 128 == 0
E -128
E +0
test_u64_block.py:40: AssertionError
-------------------------------------- Hypothesis ----------------------------------------------
Falsifying example: test_u64_block_bitmask(
self=<test_u64_block.TestU64BlockOp testMethod=test_u64_block_bitmask>,
bits=[False, False, False, False, False, False, False, True],
)
Hypothesis finds the bug in a fraction of a second, but, more importantly, it then works harder to report a minimal counter-example.4 With all but the last mask set to 0, it’s easy to guess that we’re probably ignoring the value of the last mask (and maybe more), which would be why we found a bitmask of 0 rather than 128.
Why Hypothesis?
So far this is all regular property-based testing, with a hint of more production-readiness than we’ve come to expect from clever software correctness tools. What really sold me was Hypothesis’s stateful testing capability, which makes it easy to test not only individual functions, but also methods on stateful objects.
For example, here is the test code for our specialised representation of lists of row ids (of 64-bit integers),
which reuses internal bits as inline storage in the common case when the list is small (the type is called entry because it’s
a pair of a key and a list of values).
# test_inlined_list.py
class PregrouperEntryList(RuleBasedStateMachine):
"""Populate a pregrouper entry in LIST mode; it should have all row
ids in insertion order.
"""
MODE = C.PREGROUP_MODE_LIST
U64S = st.one_of(
# Either one of the sentinel values
st.sampled_from(list(range(2 ** 64 - 3, 2 ** 64))),
# or any row id.
st.integers(min_value=0, max_value=2 ** 64 - 1),
)
def __init__(self):
super().__init__()
self.rows = []
self.error = FFI.new("crdb_error_t *")
self.entry = None
def teardown(self):
if self.entry is not None:
C.pregrouper_entry_deinit(self.entry, self.MODE)
self.entry = None
def perror(self, name):
return "%s: %s %i" % (name, FFI.string(self.error.message), self.error.error)
@precondition(lambda self: self.entry is None)
@rule(row=U64S)
def create_entry(self, row):
self.entry = FFI.new("struct crdb_pregrouper_entry *")
C.pregrouper_entry_init(self.entry, [row])
self.rows = [row]
@precondition(lambda self: self.entry)
@rule(row=U64S)
def add_row(self, row):
assert C.pregrouper_entry_add_row(
self.entry, self.MODE, [row], self.error
), self.perror("add_row")
self.rows.append(row)
@precondition(lambda self: self.entry)
@rule()
def finalize(self):
assert C.pregrouper_entry_finalize(
self.entry, self.MODE, self.error
), self.perror("finalize")
@precondition(lambda self: self.entry)
@rule()
def check(self):
self.finalize()
assert self.rows == [
self.entry.payload.list.values[i]
for i in range(self.entry.payload.list.n_entries)
]
TestPregrouperEntryList = PregrouperEntryList.TestCase
Most @rule-decorated methods call a C function
before updating a Python-side model of the values we expect to find in the list.
The @rule decorator mark methods that Hypothesis may call to generate examples;
the decorator’s arguments declare how each method should be invoked.
Some methods also have a @precondition decorator to specify when they can be invoked
(a @rule without any @precondition is always safe to call).
There is one method (create_entry) to create a new list populated with an initial row id,
another (add_row) to add a row id to the list,
one to finalize the list, something which should always be safe to call and must be done before reading the list’s contents
(finalizing converts away from the inline representation),
and a check to compare the list of row ids in C to the one we maintained in Python.
Row ids are arbitrary 64-bit integers, so we could simply
ask Hypothesis to generate integers in \([0, 2^{64} - 1]\).
However, we also know that the implementation uses high row id values around
UINT64_MAX as sentinels in its implementation of inline storage, as shown below.
struct inlined_list {
union {
uint64_t data[2];
struct {
uint64_t *arr;
unsigned int capacity;
unsigned int length;
};
};
uint64_t control;
};
Out of line list Inline list of 2 Inline list of 3
---------------- ---------------- ----------------
data[0]: arr elt #0 elt #0
data[1]: capacity & length elt #1 elt #1
control: UINT64_MAX UINT64_MAX - 2 elt #2 < UINT64_MAX - 2
That’s why we bias the data generation towards row ids that could also be mistaken for sentinel values: we generate each row id by either sampling from a set of sentinel-like values, or by sampling from all 64-bit integers. This approach to defining the input data is decidedly non-magical, compared to the way I work with fuzzers. However, fuzzers also tend to be slow and somewhat fickle. I think it makes sense to ask programmers to think about how their own code should be tested, instead of hoping a computer program will eventually intuit what edge cases look like.5
It’s pretty cool that Hypothesis will now generate a bunch of API calls for me, but, again, what makes Hypothesis really valuable is the way it minimises long sequences of random calls into understandable counter-examples. Here’s what Hypothesis/pytest reports when I remove a guard that saves us from writing a row id to a control word when that id would look like a sentinel value.
self = PregrouperEntryList({})
@precondition(lambda self: self.entry)
@rule()
def check(self):
self.finalize()
> assert self.rows == [
self.entry.payload.list.values[i]
for i in range(self.entry.payload.list.n_entries)
]
E AssertionError: assert [184467440737...4073709551613] == [184467440737...4073709551613]
E Left contains one more item: 18446744073709551613
E Full diff:
E - [18446744073709551613, 18446744073709551613, 18446744073709551613]
E ? ----------------------
E + [18446744073709551613, 18446744073709551613]
test_pregroup_merge.py:81: AssertionError
------------------------------------------ Hypothesis ------------------------------------------
Falsifying example:
state = PregrouperEntryList()
state.create_entry(row=18446744073709551613)
state.add_row(row=18446744073709551613)
state.add_row(row=18446744073709551613)
state.check()
state.teardown()
We can see that we populated a list
thrice with the same row id, 18446744073709551613,
but only found it twice in the final C-side list.
That row id is \(2^{64} - 3,\) the value we use to denote inline lists of two values.
This drawing shows how the last write ended up going to a control word where it was treated as a sentinel, making the inline representation look
like a list of two values, instead of three values.
Bad list of 3 Identical list of 2
---------------- ---------------------
data[0]: UINT64_MAX - 2 UINT64_MAX - 2
data[1]: UINT64_MAX - 2 UINT64_MAX - 2
control: UINT64_MAX - 2 (payload) UINT64_MAX - 2 (sentinel)
I restored the logic to prematurely stop using the inline representation and convert to a heap-allocated vector whenever the row value would be interpreted as a sentinel, and now Hypothesis doesn’t find anything wrong. We also know that this specific failure is fixed, because Hypothesis retries examples from its failure database6 on every rerun.
But Hypothesis is a Python library?!
There are multiple language-specific libraries under the Hypothesis project; none of them is in C, and only the Python implementation is actively maintained. One might think that makes Hypothesis inappropriate for testing C. However, the big ideas in Hypothesis are language-independent. There is a practical reason for the multiple implementations: for a tool to be really usable, it has to integrate well with the programming language’s surrounding ecosystem. In most languages, we also expect to write test code in the same language as the system under test.
C (and C++, I would argue) is an exception. When I tell an experienced C developer they should write test code in Python, I expect a sigh of relief. The fact that Hypothesis is written in Python, as opposed to another managed language like Ruby or C# also helps: embedding and calling C libraries is Python’s bread and butter. The weak state of C tooling is another factor: no one has a strong opinion regarding how to invoke C test code, or how the results should be reported. I’ll work with anything standard enough (e.g., pytest’s JUnit dump) to be ingested by Jenkins.
The last thing that sealed the deal for me is Python’s CFFI. With that library, I simply had to make sure my public header files were clean enough to be parsed without a full-blown compiler; I could then write some simple Python code to strip away preprocessor directive, read headers in dependency order, and load the production shared object, without any test-specific build step. The snippets of test code above don’t look that different from tests for a regular Python module, but there’s also a clear mapping from each Python call to a C call. The level of magic is just right.
There is one testing concern that’s almost specific to C and C++ programs:
we must be on the lookout for memory management bugs.
For that, we use our ASan
build and bubble up some issues (e.g., read overflows or leaks) back to Python;
everything else results in an abort(), which, while suboptimal for minimisation, is still useful.
I simplified our test harness for the Heartbleed experiment;
see below for gists that anyone can use as starting points.
Why not fuzzing?
I abused fuzzers a lot in the past, mostly because the tooling was there and it was trivial to burn hundreds of CPU-hours. Technical workarounds seemed much easier than trying to add support for actual property-based testers, so I would add domain specific assertions in order to detect more than crash conditions, and translate bytes into more structured inputs or even convert them to series of method calls. Now that I don’t have access to prebuilt infrastructure for fuzzers, that approach doesn’t make as much sense. That’s particularly true when byte arrays don’t naturally fit the entry point: I spent a lot of time making sure the fuzzer was exercising branches in the system under test, not the test harness, and designing input formats such that common fuzzer mutations, e.g., removing a byte, had a local effect and not, e.g., cause a frameshift mutation for the rest of the input… and that’s before considering the time I wasted manually converting bytes to their structured interpretation on failures.
Hypothesis natively supports structured inputs and function calls, and reports buggy inputs in terms of these high level concepts. It is admittedly slower than fuzzers, especially when compared to fuzzers that (like Hypothesis) don’t fork/exec for each evaluation. I’m comfortable with that: my experience with NP-Hard problems tells me it’s better to start by trying to do smart things with the structure of the problem, and later speed that up, rather than putting all our hopes in making bad decisions really really fast. Brute force can only do so much to an exponential-time cliff.
I had one niggling concern when leaving the magical world of fuzzers for staid property-based testing. In some cases, I had seen coverage information steer fuzzers towards really subtle bugs; could I benefit from the same smartness in Hypothesis? That’s how I came up with the idea of simulating a reasonable testing process that ought to find CVE-2014-0160, Heartbleed.
Role-playing CVE-2014-0160
CVE-2014-0160 a.k.a. Heartbleed is a read heap overflow in OpenSSL 1.0.1 (\(\leq\) 1.0.1f) that leaks potentially private data over the wire. It’s a straightforward logic bug in the implementation of RFC 6520, a small optional (D)TLS extension that lets clients or servers ask for a ping. The Register has a concise visualisation of a bad packet. We must send correctly sized packets that happen to ask for more pingback data than was sent to OpenSSL.
State of the art fuzzers like AFL or Honggfuzz find that bug in seconds when given an entry point that passes bytes to the connection handler, like data that had just come over the wire. When provided with a corpus of valid messages, they’re even faster.
It’s a really impressive showing of brute force that these programs to come up with almost valid packets so quickly, and traditional property-based testing frameworks are really not up to that level of magic. However, I don’t find the black box setting that interesting. It’s probably different for security testing, since not leaking invalid data is apparently seen as a feature one can slap on after the fact: there are so many things to test that it’s probably best to focus on what fuzzing can easily find, and, in any case, it doesn’t seem practical to manually boil that ocean one functionality at a time.
From a software testing point of view however, I would expect the people who send in a patch to implement something like the Heartbeat extension to also have a decent idea how to send bytes that exercise their new code. Of course, a sufficiently diligent coder would have found the heap overflow during testing, or simply not have introduced that bug. That’s not a useful scenario to explore; I’m interested in something that does find Heartbleed, and also looks like a repeatable process. The question becomes “Within this repeatable process, can branch coverage feedback help Hypothesis find Heartbeat?”
Here’s what I settled on: let’s only assume the new feature code also comes with a packet generator to exercise that code. In Hypothesis, it might look like the following.
# test_with_grammar.py
class GrammarTester(sanitizers.RuleBasedStateMachine):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# Avoid reporting initialisers as leaks.
with sanitizers.leaky_region():
assert C.LLVMFuzzerTestOneInput(b"", 0) == 0
self.buf = b""
def teardown(self):
assert C.LLVMFuzzerTestOneInput(self.buf, len(self.buf)) == 0
@initialize(
tls_ver=st.sampled_from([1, 2, 3]),
payload=st.binary(),
padding=st.binary(min_size=16),
)
def add_heartbeat(self, tls_ver, payload, padding):
hb_payload = bytes([0x01]) + struct.pack(">H", len(payload)) + payload + padding
self.buf += bytes([0x18, 0x03, tls_ver])
self.buf += struct.pack(">H", len(hb_payload))
self.buf += hb_payload
We have a single rule to initialize the test buffer with a valid heartbeat packet, and we send the whole buffer to a standard fuzzer entry point at the end. In practice, I would also ask for some actual assertions that the system under test handles the packets correctly, but that’s not important when it comes to Heartbleed: we just need to run with ASan and look for heap overflows, which are essentially never OK.
Being able to provide a happy-path-only “test” like the above should be less than table stakes in a healthy project. Let’s simulate a bug-finding process that looks for crashes after adding three generic buffer mutating primitives: one that replaces a single byte in the message buffer, another one that removes some bytes from the end of the buffer, and a last one that appends some bytes to the buffer.
# test_with_grammar.py
class GrammarTester(sanitizers.RuleBasedStateMachine):
...
@precondition(lambda self: self.buf)
@rule(data=st.data(), value=st.integers(min_value=0, max_value=255))
def replace_byte(self, data, value):
index = data.draw(st.integers(min_value=0, max_value=len(self.buf) - 1))
prefix = self.buf[0:index]
suffix = self.buf[index + 1 :]
self.buf = prefix + bytes([value]) + suffix
@precondition(lambda self: self.buf)
@rule(data=st.data())
def strip_suffix(self, data):
count = data.draw(st.integers(min_value=1, max_value=len(self.buf)))
self.buf = self.buf[0:-count]
@rule(suffix=st.binary(min_size=1))
def add_suffix(self, suffix):
self.buf += suffix
Given the initial generator rules and these three mutators, Hypothesis will assemble sequences of calls to create and mutate buffers before sending them to OpenSSL at the end of the “test.”
The first time I ran this, Hypothesis found the bug in a second or two
==12810==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x62900012b748 at pc 0x7fb70d372f4e bp 0x7ffe55e56a30 sp 0x7ffe55e561e0
READ of size 30728 at 0x62900012b748 thread T0
0x62900012b748 is located 0 bytes to the right of 17736-byte region [0x629000127200,0x62900012b748)
allocated by thread T0 here:
#0 0x7fb70d3e3628 in malloc (/usr/lib/x86_64-linux-gnu/libasan.so.5+0x107628)
#1 0x7fb7058ee939 (fuzzer-test-suite/openssl-1.0.1f-fsanitize.so+0x19a939)
#2 0x7fb7058caa08 (fuzzer-test-suite/openssl-1.0.1f-fsanitize.so+0x176a08)
#3 0x7fb7058caf41 (fuzzer-test-suite/openssl-1.0.1f-fsanitize.so+0x176f41)
#4 0x7fb7058a658d (fuzzer-test-suite/openssl-1.0.1f-fsanitize.so+0x15258d)
#5 0x7fb705865a12 (fuzzer-test-suite/openssl-1.0.1f-fsanitize.so+0x111a12)
#6 0x7fb708326deb in ffi_call_unix64 (/home/pkhuong/follicle/follicle/lib/Python3.7/site-packages/.libs_cffi_backend/libffi-806b1a9d.so.6.0.4+0x6deb)
#7 0x7fb7081b4f0f (<unknown module>)
and then spent the 30 seconds trying to minimise the failure. Unfortunately, it seems that ASan tries to be smart and avoids reporting duplicate errors, so minimisation does not work for memory errors. It also doesn’t matter that much if we find a minimal test case: a core dump and a reproducer is usually good enough.
You can find the complete code for GrammarTester, along with the ASan wrapper, and CFFI glue in this gist.
For the rest of this post, we’ll make ASan crash on the first error, and count the number of test cases generated (i.e., the number of calls into the OpenSSL fuzzing entry point) until ASan made OpenSSL crash.
How can we do better with hardware tracing?
Intel chips have offered BTS, a branch trace store, since Nehalem (2008-9), if not earlier. BTS is slower than PT, its full blown hardware tracing successor, and only traces branches, but it does so in a dead simple format. I wrapped Linux perf’s interface for BTS in a small library; let’s see if we can somehow feed that trace to Hypothesis and consistently find Heartbeat faster.
But first, how do fuzzers use coverage information?
A lot of the impressive stuff that fuzzers find stems from their ability to infer the constants that were compared with the fuzzing input by the system under test. That’s not really that important when we assume a more white box testing setting, where the same person or group responsible for writing the code is also tasked with testing it, or at least specifying how to do so.
Apart from guessing what valid inputs look like, fuzzers also use branch coverage information to diversify their inputs. In the initial search phase, none of the inputs cause a crash, and fuzzers can only mutate existing, equally non-crashy, inputs or create new ones from scratch. The goal is to maintain a small population that can trigger all the behaviours (branches) we’ve observed so far, and search locally around each member of that population. Pruning to keep the population small is beneficial for two reasons: first, it’s faster to iterate over a smaller population, and second, it avoids redundantly exploring the neighbourhood of nearly identical inputs.
Of course, this isn’t ideal. We’d prefer to keep one input per program state, but we don’t know what the distinct program states are. Instead, we only know what branches we took on the way to wherever we ended up. It’s as if we were trying to generate directions to every landmark in a city, but the only feedback we received was the set of streets we walked on while following the directions. That’s far from perfect, but, with enough brute force, it might just be good enough.
We can emulate this diversification and local exploration logic with multi-dimensional Targeted example generation, for which Hypothesis has experimental support.
We’ll assign an arbitrary unique label to each origin/destination pair we observe via BTS, and assign a score of 1.0 to every such label (regardless of how many times we observed each pair). Whenever Hypothesis compares two score vectors, a missing value is treated as \(-\infty\), so, everything else being equal, covering a branch is better than not covering it. After that, we’ll rely on the fact that multidimensional discrete optimisation is also all about maintaining a small but diverse population: Hypothesis regularly prunes redundant examples (examples that exercises a subset of the branches triggered by another example), and generates new examples by mutating members of the population. With our scoring scheme, the multidimensional search will split its efforts between families of examples that trigger different sets of branches, and will also stop looking around examples that trigger a strict subset of another example’s branches.
Here’s the plan to give BTS feedback to Hypothesis and diversify its initial search for failing examples.
I’ll use my libbts to wrap perf syscalls into something usable,
and wrap that in Python to more easily gather origin/destination pairs.
Even though I enable BTS tracing only around FFI calls,
there will be some noise from libffi, as well as dummy transitions for interrupts or context switches; bts.py attempts to only consider interesting branches
by remembering the set of executable mappings present at startup,
before loading the library under test,
and dropping jumps to or from addresses that were mapped at startup
(presumably, that’s from the test harness), or invalid zero or negative addresses
(which I’m pretty sure denote interrupts and syscalls).
We’ll then wrap the Python functions that call into OpenSSL to record the set of branches executed during that call,
and convert that set to a multidimensional score at the end of the test, in the teardown method.
The only difference is in the __init__ method, which must also reset BTS state,
and in the teardown method, where we score the example if it failed to crash.
# test_with_grammar_bts.py
class GrammarBtsTester(sanitizers.RuleBasedStateMachine):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
bts.reset()
with sanitizers.leaky_region():
assert C.LLVMFuzzerTestOneInput(b"", 0) == 0
bts.update_useless_edges()
bts.reset()
self.buf = b""
def teardown(self):
assert C.LLVMFuzzerTestOneInput(self.buf, len(self.buf)) == 0
# bts.report() returns a set of control flow edge ids.
for i in bts.report():
target(1.0, str(i))
bts.teardown()
...
Let’s instrument the teardown methods to print “CHECK” and flush before every call to the fuzzing entry point,
and make sure ASan crashes when it finds an issue.
We’ll run the test files, grep for “CHECK”, and, assuming we don’t trigger into any runtime limit,
find out how many examples Hypothesis had to generate before causing a crash.
I ran this 12000 times for both test_with_grammar.py and test_with_grammar_bts.py.
Let’s take a look at the empirical distribution functions for the number of calls until a crash, for test_with_grammar.py (grammar)
and test_with_grammar_bts.py (bts).
There’s a cross-over around 100 calls: as long as we have enough time for least 100 calls to OpenSSL, we’re more likely to find Heartbleed with coverage feedback than by rapidly searching blindly. With fewer than 100 calls, it seems likely that branch coverage only guides the search towards clearly invalid inputs that trigger early exit conditions. Crucially, the curves are smooth and tap out before our limit of 10000 examples per execution, so we’re probably not measuring a side-effect of the experimental setup.
In theory, the distribution function for the uninstrumented grammar search should look a lot like a geometric distribution,
but I don’t want to assume too much of the bts implementation. Let’s confirm our gut feeling in R with a simple non-parametric test,
the Wilcoxon rank sum test, an unpaired analogue to the sign test:
> wilcox.test(data$Calls[data$Impl == 'bts'], data$Calls[data$Impl == 'grammar'], 'less')
Wilcoxon rank sum test with continuity correction
data: data$Calls[data$Impl == "bts"] and data$Calls[data$Impl == "grammar"]
W = 68514000, p-value = 4.156e-11
alternative hypothesis: true location shift is less than 0
We’re reasonably certain that the number of calls for a random run of bts is more
frequently less than the number of calls for an independently chosen random run of grammar
than the opposite. Since the tracing overhead is negligible,
this means branch feedback saves us time more often than not.
For the 24 000 separate runs we observed,
bts is only faster 52% of the time,
but that’s mostly because both distributions of calls to the system under test go pretty high.
On average, vanilla Hypothesis, without coverage feedback, found the vulnerability after 535 calls to OpenSSL;
with feedback, Hypothesis is 11.5% faster on average, and only needs 473 calls.
Time to use this in anger
We have been using this testing approach (without branch coverage) at Backtrace for a couple months now, and it’s working well as a developer tool that offers rapid feedback, enough that we’re considering running these tests in a commit hook. Most of the work involved in making the approach useful was just plumbing, e.g., dealing with the way ASan reports errors, or making sure we don’t report leaks that happen in Python, outside the system under test. Once the commit hook is proven solid, we’ll probably want to look into running tests in the background for a long time. That’s a very different setting from pre-commit or commit -time runs, where every bug is sacred. If I let something run over the weekend, I must be able to rely on deduplication (i.e., minimisation is even more useful), and I will probably want to silence or otherwise triage some issues. That’s the sort of thing Backtrace already handles, so we are looking into sending Hypothesis reports directly to Backtrace, the same way we do for clang-analyzer reports and for crashes or leaks found by ASan in our end-to-end tests.
The challenges are more research-y for coverage feedback. There’s no doubt a lot of mundane plumbing issues involved in making this feedback robust (see, e.g., the logic in bts.py to filter out interrupts and branches from the kernel, or branches from code that’s probably not in the system under test). However, there’s also a fundamental question that we unfortunately can’t answer by copying fuzzers.
How should we score coverage over multiple calls? After all, the ability to test a stateful interface via a sequence of method calls and expections is what really sold me on Hypothesis. Fuzzers have it easy: they assume each call is atomic and independent of any other call to the system under test, even when they don’t fork for each execution. This seems like a key reason why simple coverage metrics work well in fuzzers, and I don’t know that we can trivially port ideas from fuzzing to stateful testing.
For example, my first stab at this experiment found no statistically significant improvement from BTS feedback. The only difference is that the assertion lived in a check rule,
and not in the teardown method, which let Hypothesis trigger a call to OpenSSL at various points in the buffer mutation sequence… usually a good thing for test coverage.
I’m pretty sure the problem is that a single example could collect “points” for covering branches in multiple unrelated calls to OpenSSL,
while we would rather cover many branches in a single call.
What does it mean for stateful testing, where we want to invoke different functions multiple times in a test?
I have no idea; maybe we should come up with some synthetic stateful testing benchmarks that are expected to benefit from coverage information. However, the experiment in this post gives me hope that there exists some way to exploit coverage information in stateful testing. The MIT-licensed support code in this gist (along with libbts) should give you all a headstart to try more stuff and report your experiences.
Thank you David, Ruchir, Samy, and Travis for your comments on an early draft.
Appendix: How to get started with your own project
In a performance-oriented C library, the main obstable to testing with Hypothesis and CFFI will probably be that the headers are too complex for pycparser. I had to use a few tricks to make ours parse.
First, I retro-actively imposed more discipline on what was really public and what implementation details should live in private headers: we want CFFI to handle every public header, and only some private headers for more targeted testing. This separation is a good thing to maintain in general, and, if anything, having pycparser yell at us when we make our public interface depend on internals is a net benefit.
I then had to reduce our reliance on the C preprocessor. In some cases,
that meant making types opaque and adding getters.
In many more cases, I simply converted small #defined integer constants to
anonymous enums enum { CONSTANT_FOO = ... }.
Finally, especially when testing internal functionality, I had to remove
static inline functions.
That’s another case where pycparser forces us to maintain cleaner headers,
and the fix is usually simple:
declare inline (not static) functions in the header,
#include a .inl file with the inline definition (we can easily drop directives in Python),
and re-declare the function as extern in the main source file for that header.
With this approach, the header can focus on documenting the interface,
the compiler still has access to an inline definition,
and we don’t waste instruction bytes on duplicate out-of-line definitions.
/* u64_block.h */
/**
* This file documents the external interface.
*/
inline uint8_t crdb_u64_block_lt(const uint64_t *, uint64_t k);
#include "u64_block.inl" /* Stripped in Python. */
/* u64_block.inl */
/**
* Describe implementation details here.
*/
inline uint8_t
crdb_u64_block_lt(const uint64_t *block, uint64_t k)
{
....
}
/* u64_block.c */
#include "u64_block.h"
/* Provide the unique out-of-line definition. */
uint8_t crdb_u64_block_lt(const uint64_t *block, uint64_t k);
That doesn’t always work, mostly because regular inline functions aren’t
supposed to call static inline functions. When I ran into that issue,
I either tried to factor the more complex slow path out to an out-of-line definition,
or, more rarely, resorted to CPP tricks (also hidden in a .inl file) to rewrite calls to
extern int foo(...)
with macros like #define foo(...) static_inline_foo(__VA_ARGS__).
All that work isn’t really testing overhead; they’re mostly things that library maintainers should do, but are easy to forget when when we only hear from C programmers.
Once the headers were close enough to being accepted by CFFI, I closed the gap with string munging in Python. All the tests depend on the same file that parses all the headers we care about in the correct order and loads the shared object. Loading everything in the same order also enforces a reasonable dependency graph, another unintended benefit. Once everything is loaded, that file also post-processes the CFFI functions to hook in ASan (and branch tracing), and strip away any namespacing prefix.
The end result is a library that’s more easily used from managed languages like Python, and which we can now test it like any other Python module.
The graph shows time in terms of calls to the SUT, not real time. However, the additional overhead of gathering and considering coverage information is small enough that the feedback also improves wallclock and CPU time. ↩︎
High level matchers like GMock’s help, but they don’t always explain why a given matcher makes sense. ↩︎
There’s also a place for smart change detectors, especially when refactoring ill understood code. ↩︎
I had to disable the exhaustive list of examples to benefit from minimisation. Maybe one day I’ll figure out how to make Hypothesis treat explicit examples more like an initial test corpus. ↩︎
That reminds me of an AI Lab Koan. «In the days when Sussman was a novice, Minsky once came to him as he sat hacking at the PDP-6. “What are you doing?” asked Minsky. “I am training a randomly wired neural net to play Tic-tac-toe,” Sussman replied. “Why is the net wired randomly?” asked Minsky. Sussman replied, “I do not want it to have any preconceptions of how to play.” Minsky then shut his eyes. “Why do you close your eyes?” Sussman asked his teacher. “So that the room will be empty,” replied Minsky. At that moment, Sussman was enlightened.» ↩︎
The database is a directory of files full of binary data. The specific meaning of these bytes depends on the Hypothesis version and on the test code, so the database should probably not be checked in. Important examples (e.g., for regression testing) should instead be made persistent with
@exampledecorators. Hypothesis does guarantee that tese files are always valid (i.e., any sequence of bytes in the database will result in an example that can be generated by the version of Hypothesis and of the test code that reads it), so we don’t have to invalidate the cache when we update the test harness. ↩︎